How canary judgment works
Note: Automated canary analysis in Spinnaker is designed to support pluggable judges. This document describes how the default judge (NetflixACAJudge) works.
To assess the quality of a canary deployment against a baseline, metrics from both deployments are compared in order to check for significant degradation. This is done in two phases:
Metric collection (retrieval)
This phase retrieves the key metrics from the baseline and canary deployments. These metrics are typically stored in a time-series database, and include a set of tags or annotations that identify which deployment the data was collected from (canary or baseline).
This phase is performed by Kayenta, not by the judge. Besides the default judge, it is possible to plug in a custom judge, and metric collection is not the responsibility of the judge. The judge merely receives timeseries from Kayenta and analyzes those.
Judgment
In this phase Spinnaker compares those metrics and renders a decision to pass or fail the canary (that is, was there a significant degradation in the metrics?) The judgment can also be configured to continue on with a canary when the result is “marginal.”
The judgment consists of four main steps, and they’re described below.
Step 1: Data validation
Data validation ensures that there’s data for the baseline and canary metrics before analysis begins.
If metric collection returns an empty array for either the baseline or canary
metric (or both) the metric is labeled NODATA and analysis moves on to the
next metric.
Note that some metrics might have no data, but for good reasons. For example, an
error counter has no value if there are no failures. For this reason the judge
does not automatically fail the canary for NODATA.
Step 2: Data cleaning
This step prepares the raw metrics for comparison. This entails handling missing values from the input.
Note that there are different strategies for handling missing values based on the type of metric. For example, missing values, represented as NaNs, may be replaced with zeros for error metrics while they may be imputed or removed for other types of metrics. In addition, the data cleaning step can, optionally, remove outliers from the data before comparison.
Step 3: Metric comparison (classification)
This is the step that compares the canary and baseline data for each included metric. The output of this step is a classification, for each metric indicating if there is a significant difference between the canary and baseline.
Each metric is classified as either Pass, High, or Low, as shown in the screen shot below.
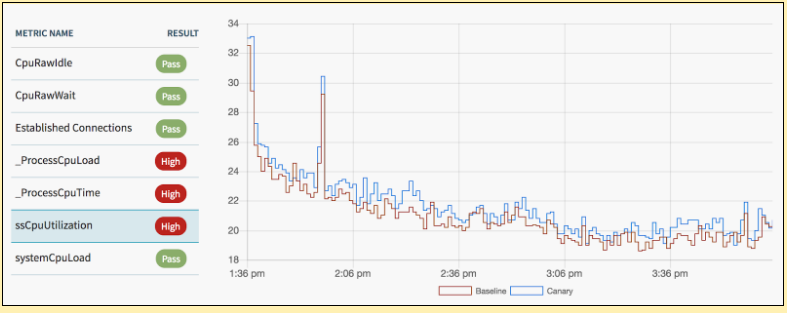
The primary metric comparison algorithm (classifier) in Kayenta uses a nonparametric statistical test to check for a significant difference between the canary and baseline metrics.
Step 4: Score computation
After each metric is classified, a final score is computed which represents how similar the canary is to the baseline. A metric group’s score is calculated as the ratio of “Pass” metrics out of the total number of metrics.
For example, if 9 of 10 metrics are classified as “Pass,” the score is 90%. The threshold score for overall canary pass, marginal, or fail is specified in the canary configuration .
While there are more complex scoring methodologies, the default judge (NetflixACAJudge) is biased toward techniques that are simple to interpret and understand; understanding why a decision was made is important to the success of Automated Canary Analysis.