Artifacts from Build Triggers
When an external CI system triggers a pipeline, Spinnaker can use the CI build information to inject relevant artifacts into the pipeline.
The Legacy Artifacts UI has been removed. These pages refer to the newer Artifacts UI. For information about the legacy Artifacts UI, see this page .
A Spinnaker artifact is a named JSON object that refers to an external resource.
Spinnaker supports a wide range of providers. An artifact can reference any of many different external resources, such as…
Each of these could be fetched using a URI and used within a pipeline, but a URI alone can omit other important information about the resource. You may wish to also fetch provenance information such as the commit that triggered the resource’s build, or to store information about the account that has permission to download the resource.
To incorporate metadata such as this along with the resource’s URI, Spinnaker artifacts follow a particular specification that includes the human-readable name of the artifact, its URI, and any other applicable metadata. This is called “artifact decoration”. Every Spinnaker artifact–whether supplied to a pipeline, accessed within a pipeline, or produced by a pipeline–follows this specification.
Keep in mind that the artifact in Spinnaker is a reference to an external resource–it is not the resource itself. The resource itself could be of any type supported by Spinnaker; the artifact is the named JSON object that contains information about the resource.
If using a version of Spinnaker prior to 1.20, enable support for the standard artifacts UI:
hal config features edit --artifacts-rewrite true
If using Spinnaker 1.20 or later, support for the standard artifacts UI is enabled by default.
If you were using Spinnaker 1.19 or earlier with the legacy artifacts UI enabled, you will notice several changes upon upgrading to 1.20. For example, there is no longer a separate Expected Artifacts section when configuring a pipeline. Instead, you can add, edit, and remove expected artifacts from the Trigger Constraints section of each trigger. If an artifact is not associated with a trigger, it is no longer editable from the pipeline configuration view, and we recommend defining it inline in the stage that consumes it instead.
For the 1.20 release only, you can add the following to your settings-local.js
to revert to the legacy artifacts UI:
window.spinnakerSettings.feature.legacyArtifactsEnabled = true;
As an example, an object stored in Google Cloud Storage (GCS) might be accessed using the following Spinnaker artifact:
{
"type": "gcs/object",
"reference": "gs://bucket/file.json#135028134000",
"name": "gs://bucket/file.json",
"version": "135028134000"
"location": "us-central1"
}
As another example, a Docker image might be accessed using the following artifact:
{
"type": "docker/image",
"reference": "gcr.io/project/image@sha256:29fee8e284",
"name": "gcr.io/project/image",
"version": "sha256:29fee8e284"
}
The fields that make up a Spinnaker artifact are described below.
| Field | Explanation | Notes |
|---|---|---|
type | How the external resource is classified. (This allows for easy distinction between Docker images and Debian packages, for example). | |
reference | The URI used to fetch the resource. | |
artifactAccount | The Spinnaker artifact account that has permission to fetch the resource. | |
version | The version of the resource. (By convention, version should only be compared between artifacts of the same type and name.) | Optional. |
provenance | The relevant URI from the system that produced the resource. (This is used for deep-linking into other systems from Spinnaker.) | Optional. |
metadata | Arbitrary key / value metadata pertaining to the resource. (This can be useful for scripting within pipeline stages.) | Optional. |
location | The region, zone, or namespace of the resource. (This does not add information to the URI, but makes multi-regional deployments easier to configure.) | Optional. |
uuid | Used for tracing the artifact within Spinnaker. | Assigned by Spinnaker. |
Within a pipeline trigger or stage, you can declare that the trigger or stage expects a particular artifact to be available. This artifact is called an expected artifact. Spinnaker compares an incoming artifact (for example, a manifest file stored in GitHub) to the expected artifact (for example, a manifest with the file path path/to/my/manifest.yml); if the incoming artifact matches the specified expected artifact, the incoming artifact is bound to that expected artifact and used by the trigger or stage.
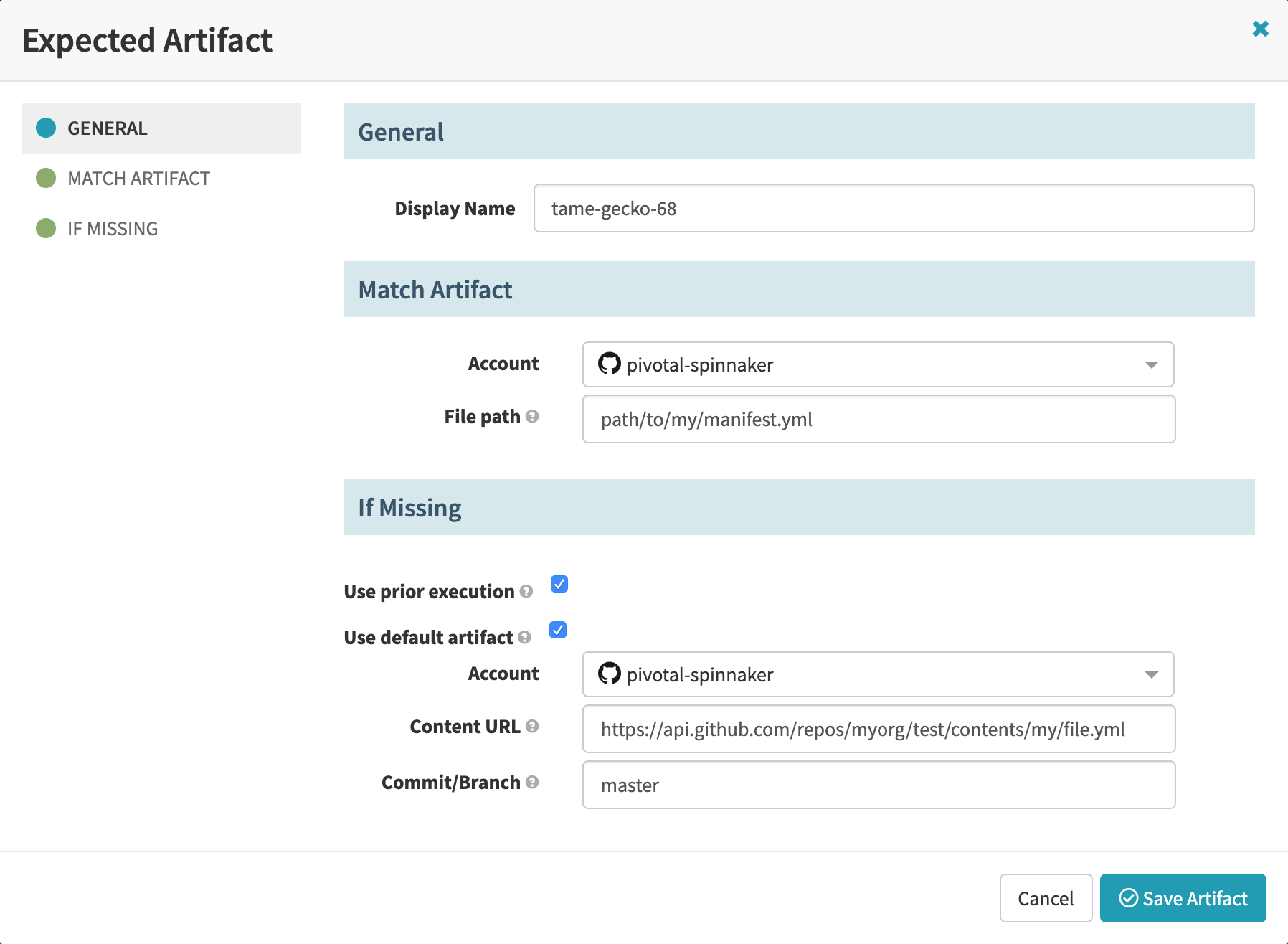
When declaring an expected artifact for a trigger, you can use fields under Match Artifact to specify metadata against which to compare the incoming artifact. This is how you can distinguish between similar artifacts coming from the same artifact account (for example, multiple manifest files stored in a single Git repository) and specify that the trigger should begin pipeline execution only if the incoming artifact matches the parameters that you provided.
In the fields under If Missing, you can provide fallback behavior for the expected artifact in case the trigger doesn’t find the desired artifact. If you enable the Use prior execution checkbox, Spinnaker will fall back to the artifact used in the last execution. If you enable the Use default artifact checkbox, Spinnaker will use a default artifact, which you can specify in the form (this allows you to provide fallback behavior for the first time a trigger is used, when there is no previous execution yet).
When an external CI system triggers a pipeline, Spinnaker can use the CI build information to inject relevant artifacts into the pipeline.
Spinnaker supports using Google App Engine artifacts several ways.
Artifacts can used for both an app’s manifest and for the deployment archive, such as a JAR file for a Java app. These both can be used in a Deploy stage.
Artifacts play an important role in the Kubernetes provider. Everything from the manifests you deploy to the Docker images or ConfigMaps they reference can be expressed or deployed in terms of artifacts.
An artifact arrives in a pipeline execution either from an external trigger (for example, a Docker image pushed to a registry) or by getting fetched by a stage. That artifact is then consumed by downstream stages based on pre-defined behavior.
Artifacts are remote, deployable resources that Spinnaker can reference.